- Published on
Creating A Japanese-English Translation Application
- Authors

- Name
- Curtis Mitchell
Note: this is a walkthrough of the JP-EN translation application that I'm no longer hosting online to save on cloud hosting fees. I assume the reader understands the main principles of deep learning and related concepts such as gradient descent and loss functions.
When deciding on a topic for my Springboard capstone project, I knew quickly that I wanted to work on a neural machine translation (NMT) model. Machine translation has been a focus of my studies within machine learning due to my facination with linguistics and learning foreign languages. I was drawn to work on a Japanese-English translator because of my familiarity with the language (I minored in Japanese in college and continue studying it in my free time) as well as curiosity to see how it would be to work with a language that does not use the Roman alphabet.
After several months of work I'm happy to share the progress I've made so far with this project. In this post I'll detail various aspects of the project from data gathering and cleaning to deployment, and I'll also give a walkthrough of the neural network architecture and ideas for future improvements to the project.
The Data
The dataset I chose to use for this project was the Japanese-English Subtitle Corpus, or JESC. This is a corpus of 2.8 million pairs of sentences taken from internet crawls of television and movie subtitles. Unlike most translation datasets, the JESC features a large amount of slang and colloquialisms which was part of its draw for me. It also did not require a large amount of processing to get it into a Python-friendly format as it came from a simple text file (as opposed to more complicated formats such as an XML document).
Preprocessing the data before feeding it to the neural network did require significant effort, however. This was largely due to some of the characteristics of Japanese text and how it gets encoded by computers. Let's go through a short description of written Japanese to get a feel for its differences from written English.
A brief overview of written Japanese
While English sentences are typically in the subject-verb-object order (“I go to the store”), Japanese is subject-object-verb (“I to the store go”). The written language uses 3 different alphabets:
Chinese characters called “kanji” (漢字) that denote ideas and thus are used to represent any words and can have multiple readings or pronunciations.
A native syllabary (meaning the characters represent whole syllables instead of individual sounds) “hiragana” (ひらがな), which is characterized by fewer lines per character than kanji and with more curved shapes. Hiragana is used for conjugation (often following kanji that form the first part of a word), grammatical parts-of-speech like adverbs and conjunctions, native words not represented by kanji, and several other purposes.
A second native syllabary “katakana” (カタカナ), characterized by few lines similar to hiragana, but with sharper lines and angles. Katakana is used for non-East Asian proper nouns and loan words, emphasizing text (like italic or bold letters in English), animal and plant names, and other uses.
Text Preprocessing
It turns out that because Japanese has multiple types of characters, native speakers can often use this feature to visually distinguish a sentence's individual words instead of using spaces as European languages use. This sentence, “I came from the supermarket”, features all three alphabets:
私はスーパーから来た。
While this visual division works fine for human readers of Japanese, it's still easier for software if it can break up English and Japanese text in similar ways, a process known in natural language processing as “tokenization”. Therefore we need a way to add spaces between logical portions of Japanese text, which can present challenges for things like compound words. For my project I used the popular NLP Python library Spacy along with the Japanese tokenizer library SudachiPy. This library actually has settings that allow you to vary the level of granularity in its tokenization. For instance, here is an example from the documentation showing the various options available to break up the word for “government official” (I opted for the middle-of-the-road option “B” in my project):
mode = tokenizer.Tokenizer.SplitMode.C
[m.surface() for m in tokenizer_obj.tokenize("国家公務員", mode)]
# -> ['国家公務員']
mode = tokenizer.Tokenizer.SplitMode.B
[m.surface() for m in tokenizer_obj.tokenize("国家公務員", mode)]
# -> ['国家', '公務員']
mode = tokenizer.Tokenizer.SplitMode.A
[m.surface() for m in tokenizer_obj.tokenize("国家公務員", mode)]
# -> ['国家', '公務', '員']
Another issue is that while Japanese has some obviously different puncuation marks (periods are “。”, for example), even punctuation that looks similar to the English counterparts (!or !) have different unicode values. Handling these as well as removing potential accented characters from the English text (i.e., turning “résumé” into “resume”) and transforming the text of both languages from Unicode into ASCII encodings was the majority of my pre-processing and text normalization work. Additionally, each sentence needs to start and end with special tokens (literally <start> and <end> in this case) as guidance for parsing each sentence.
Preparing The Text Data for Training
Since neural networks can only work with numbers, it's necessary to convert text data into numerical data for both the input language and target (or “output”) language of a NMT model. This process gives a numerical value to each unique word that appears in the data along with “word indexes” to be able to look up the words by their numerical values and vice-versa. The process also creates vectors with the same length as the longest sentence in the dataset (one for the input sentences and one for the target sentences). Each sentence is then one-hot encoded as a vector with numerical values at the space of each word and zeroes padding the vector to the maximum sentence length.
After this vectorization of the sentences has been performed, I split the data into the following ratios using Scikit-learn's train_test_split method: training data = 75%, validation data = 15%, test data = 10%. I then created a dataset using Tensorflow's tf.data.Dataset class.
Neural Network Architecture
The neural network used in this project was built using the Tensorflow framework, and the architecture I chose for this project was a sequence-to-sequence (seq2seq) model, more specifically an encoder-decoder model with attention. Seq2seq models use recurrent-neural-networks (RNNs), a natural choice for NLP problems as RNNs are capable of working with variable-length inputs and thus can handle text of various lengths. An additional appeal of RNNs, especially in NLP contexts, is that they have a sense of “memory” by being able to pass state between the layers of a neural network.
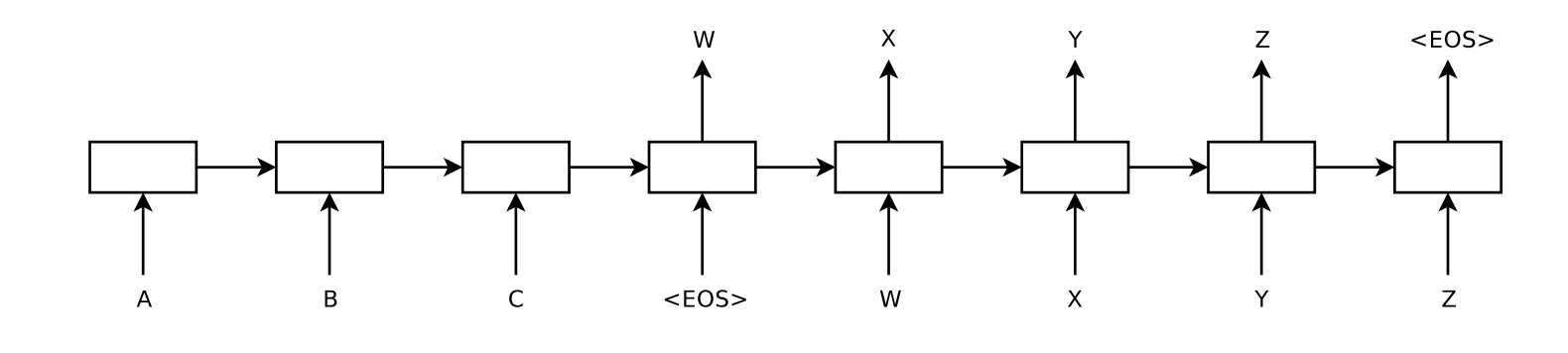
Depiction of a sequence-to-sequence model, "EOS" is "end of sentence" (Sutskever et al., 2014)
RNNs feature several sub-classes of networks such as long-short term memory networks (LSTMs). It turns out that standard RNNs have a difficult time if the space between references gets too long (an example would be having the context from the beginning of a long sentence to help translate the end of a sentence). This problem is referred to as the “long-term dependency problem”, and LSTMs were designed specifically to avoid this issue! They feature a concept called “cell state” that lets information pass between modules of a neural network to overcome the long-term dependency problem. My model specifically uses GRUs, or “Gated Recurrent Units” which, among other changes, simplifies the storing and passing around of this hidden state versus traditional LSTMs.
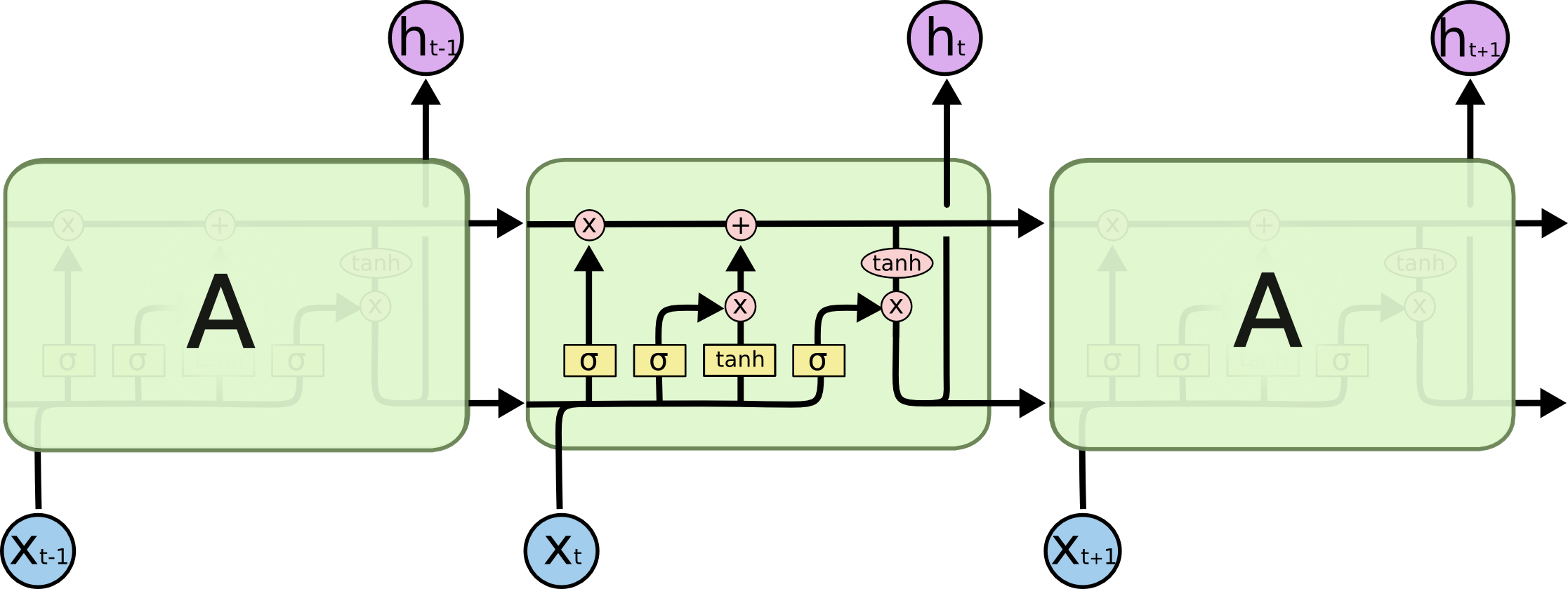
Visualization of an LSTM network cell (Source)
At the layer of the encoder-decoder part of the architecture, the encoder RNN reads in an input sentence and creates a vector representation of that sentence, which is then used by the decoder to extract a target sequence of that vector. During this process each word in the input sentence is assigned a weight value by the attention mechanism (described below), and this weight value is in turn used by the decoder to predict the next word in the target sentence.
Loss Function
This model used the sparse categorical cross-entropy method. Cross-entropy loss methods are also called “log-loss” methods and use a logarithmic function to increase the loss value as the predicted probability of an observation diverges from the actual observation. Sparse categorical cross-entropy is a specific use case for lots of categories (predicted translated words, in our case) that are represented as one-hot encodings, i.e. as vectors with a few ones and many zeros.
Attention Mechanism
The general idea of an attention mechanism is to prevent the model from associating a single vector with each sentence and use “attention weights” to influence which input vectors to prioritize and create a “context vector” that summarizes the input data received by the decoder. In encoder-decoder LSTMs without this attention mechanism, only the last hidden state value would be used to generate the context vector.
The network used in this project utilized Bahdanau attention, which works by using a linear combination of the encoder and decoder states to generate the context vector. The context vectors created by the Bahdanau attention mechanism as well as previously generated target words are then used by the model to predict a new target word. See the original paper that introduced Bahdanau attention, "Neural Machine Translation by Jointly Learning to Align and Translate", for more information.
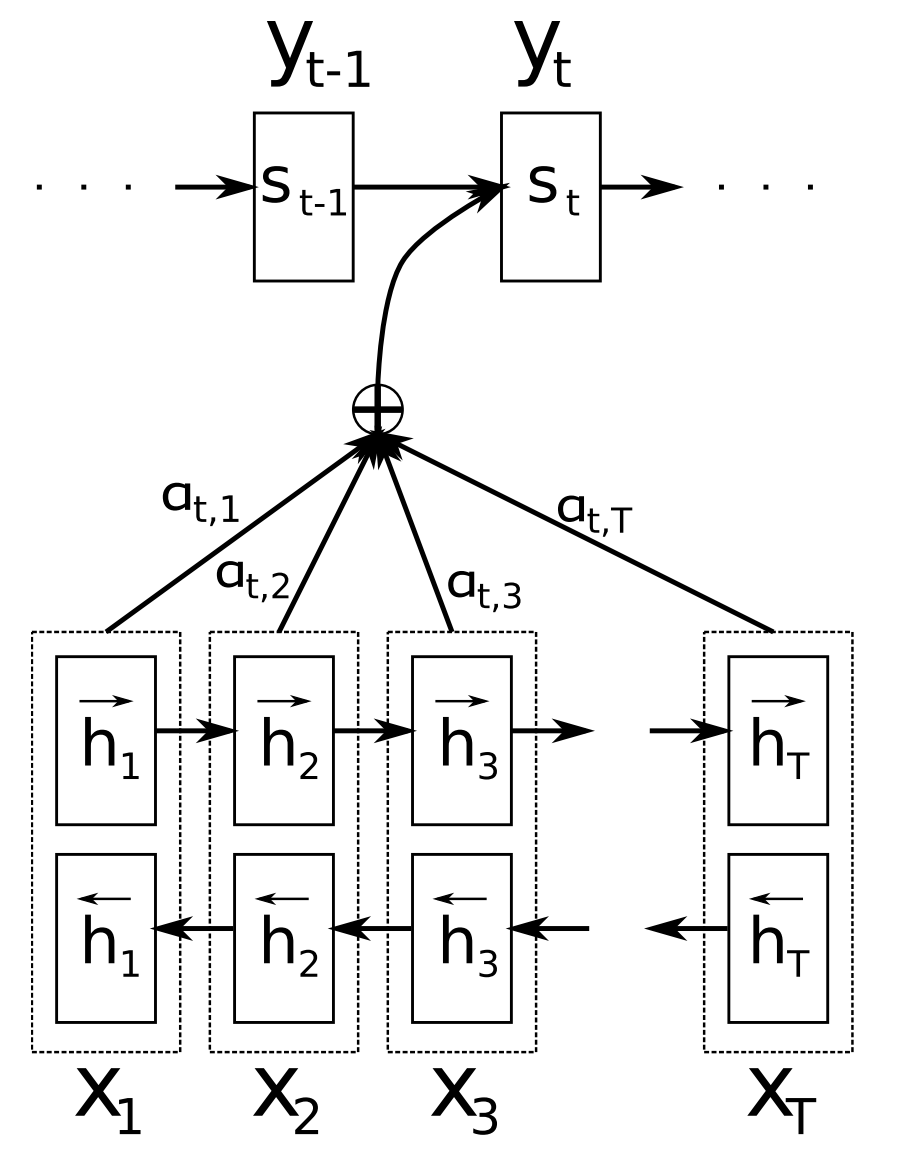
Bahdanau Attention Diagram (Bahdanau et al., 2015)
Optimizer
The optimization algorithm used in this model is the Adam optimizer. This optimizer is an extention of the stochastic gradient descent algorithm, and improves on it by using an adaptive learning rate to speed up optimization. More technically, the Adam algorithm calculates the exponential moving average of the gradient and squared gradient and uses two parameters (beta1 and beta2) to control the decay rate of these two averages. The original paper that introduced the Adam optimizer can be found here: "Adam: A Method for Stochastic Optimization".
Model Performance
This model was trained in a Jupyter notebook with an accessible GPU hosted by Paperspace (the notebook can be found here: Encoder-Decoder model for Japanese-to-English Translation). After 100 epochs that ran for about 30 hours and another 12 hours for evaluating the model on test data, the process was complete.
I evaluated the models using the METEOR metric. Unfortunately, the performance was not as great as I had hoped (it rarely is!). The average METEOR score per translation turned out to be just 0.10576, however this doesn't mean that roughly 1 in 10 words matched the expected translation. Briefly, the METEOR metric calculates the harmonic mean of unigram recall and precision together while giving more weight to recall. See my post on evaluating machine translation models here for more details: "How to Evaluate A Machine Translation Model".
Deployment
Once training and evaluation were complete, I chose to deploy this model through this site (though as of 2023 I am no longer hosting it online). After saving the weights of the model using Tensorflow's own model saving method and saving the input and target language vectorizers as pickle objects, I built a class within a Django backend that instantiates a model, uses the saved, static weights and vectorizers from the Paperspace training, and returns a predicted English translation. The entire Django application runs within a Docker container.

Data flow in the deployed application
The application has basic error handling in place on both the frontend and backend, and logging on the backend as well.
Ideas for Further Development
Even though I was not satisfied with the model performance I remembered the maxim that “perfect is the enemy of done” and decided to continue with deploying the model, as completing an end-to-end machine learning project was more important than chasing a high metric score for too long. Nevertheless I'd like to share potential ideas for improving the model's performance and additional deployment ideas.
Data
Data is the fuel of machine learning models, and one of the first steps I intend to take when returning to this project is adding additional training data. While I thought it could be an interesting feature at the time, in retrospect having a dataset like the JESC that features a lot of slang hampers the model performance from a user standpoint, and it tends to be missing a lot of common vocabulary. Widely-used translation apps like Google Translate deal mostly with formal written language, and since translation apps have set a paradigm of avoid informal speech and text I would seek out additional datasets with more standard vocabulary. I would expect having additional training and testing data like this to have the largest impact on model performance.
Another idea is changes to the data preprocessing methods, especially choosing different options for how the Japanese and English text is tokenized as I described earlier. However, I would expect these changes to have less significant affects on the score versus changes to the data and model architecture.
Architecture and Hyperparameters
While using an encoder-decoder with LSTMs/GNUs are the dominant architecture choice for a machine translation model, some changes to the architecture are worth exploring. The initial change I would make would be to use standard LSTMs instead of GNUs within the encoder and decoder, as LSTMs have been shown to have better performance than GNUs for some neural machine translation cases.
Another change would be to the attention mechanism used. While I used the Bahdanau attention mechanism here I could also explore using Luong attention, which is a newer method that attempts to improve on Bahdanau attention by simplifying the calculations of attention scores, leading to a faster and more efficient attention mechanism. It also uses the decoder's current hidden state to create the context vector, unlike the Bahdanau's use of the previously computed hidden state.
A more significant change than these architecture adjustments I've discussed so far would be to use a model utilizing transfer learning with BERT, or “Bidirectional Encoder Representations from Transformers”. Transfer learning is a technique wherein neural networks trained for one task are used for predictions on a different (but usually related) task. Transformers are a class of neural networks with the encoder-decoder pattern that deal with long-term dependencies even better than LSTMs, and BERT is a class of transformer models that show excellent performance on a variety of NLP tasks than can be used with several pretrained models. Comparing my more “from scratch” model described in this post versus a transfer-learning-with-BERT model would be a very interesting follow up to this project.
Changing the hyperparameters could also have a significant impact on performance. However, because the size of the GPU memory limited how much data I could process at a time, the primary hyperparameter I could significantly adjust would be the total number of epochs. Nonetheless there's always the chance that training on the same data for longer could lead to overfitting, and given that training for 100 epochs took well over a day, fine-tuning this value could take a significant amount of time, assuming I'm limited to working with one GPU.
Deployment
The deployment is generally working fine, although one thing I would like to add is a caching layer to avoid recomputing estimated translations for common input values. For this I would probably use Redis or a similar in-memory database to store common input-output pairs of sentences.
If usage of the app grew large enough, considering strategies for deploying, managing, and networking multiple instances of the backend application would be fun. Using Kubernetes to orchestrate multiple Docker containers would be a natural choice here, and my existing NGINX configuration could be updated to handle routing requests to multiple backend servers.
Extra Lessons Learned
I greatly enjoyed working on this project, and I learned a great deal during the process. Often when I read other project walkthroughs I wish developers would share some “war stories” of unexpected hurdles, both to avoid giving readers the impression that development is very rarely a smooth process and to help readers avoid similar pitfalls. Accordingly, here are a two interesting issues I didn't expect to run into.
So much of the material I've read about machine learning and data science says that you'll spend much more time on data cleaning and preprocessing than you expect, and that was true for me as well. One particular error I dealt with that stood out was the appearance of two line separator unicode (U+2028) characters (which I had never encountered until now) hiding in 2 Japanese sentences, which didn't show up until I saved the processed data to local files. When I loaded these files the Japanese sentences would have 2 extra instances versus the English sentences because of these line separators, giving me an “off by 2” error amongst 2.8 million sentences!
Another tool's quirks that I noticed which will save me lost time from now on is some of the nuances of working with the Large File Storage Git extension, aka git-lfs or "LFS". LFS allows you to store large files on a site like Github using pointer files while the large file itself is stored on a different server. Frequently when I would clone my project from one environment to another, say from my local computer to Paperspace, I unconciously thought the large files themselves would be included in the cloning process, but I shouldn't have been surprised in retrospect that only the pointer file would move while I would have to manually copy/paste the large files themselves!
Acknowledgements
I want to give a huge thank you to my Springboard mentor, Dhiraj Kumar. During our weekly calls (which were late in the evening for his timezone!) he would regularly provide me with suggestions and feedback that kept me moving forward when I could have gotten stuck or spent too much time on a particular aspect or another of the project. Please check out his Medium blog and YouTube channel.